6. Flask数据库¶
6.1. ORM¶
- ORM是“对象-关系-映射”的简称,主要任务是:
- 根据对象的类型生成表结构
- 将对象、列表的操作,转换为sql语句
- 将sql查询到的结果转换为对象、列表
ORM最根本目的是让习惯OOP的程序员能够不懂SQL就能利用OOP来编程,在ORM中, 可以粗略把对应关系认为:
- OOP的类对应SQL的表
- OOP的属性(一般是一个描述字段的类)对应SQL的表中的字段
- OOP的属性的属性对应SQL表字段的约束条件
- OOP的函数对应SQL的操作, 比如增删查改
- 优点 :
- 只需要面向对象编程思想, 不需要转换关系数据库操作的思想
- 不需要转换编程思想
- 甚至不需要使用sql
- 实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异
- 不在关注用的是哪种具体的数据库产品
- 通过简单的配置就可以轻松更换数据库, 减少代码修改
- 只需要面向对象编程思想, 不需要转换关系数据库操作的思想
- 缺点 :
- 可能有性能损失
6.2. Flask-SQLAlchemy¶
- SQLAlchemy是利用ORM思想实现的一个Python库
- 利用SQLAlchemy可以直接利用Python和面向对象编程方法操作数据库
- 基于关系型数据库
- Flask-SQLAlchemy是一个简化了的SQLAlchemy的Flask扩展
- 文档地址 Flask-SQLAlchey
6.3. 安装¶
为了使用Flask的数据库库,我们需要安装mysql数据库(本文以mysql为例), 然后安装flask相关插件,然后才能用。
6.3.1. Mysql安装¶
使用数据库,需要先安装一个数据库呀,你说是不?
本文以Mysql为例,mysql是免费数据库,不花钱,随便装。
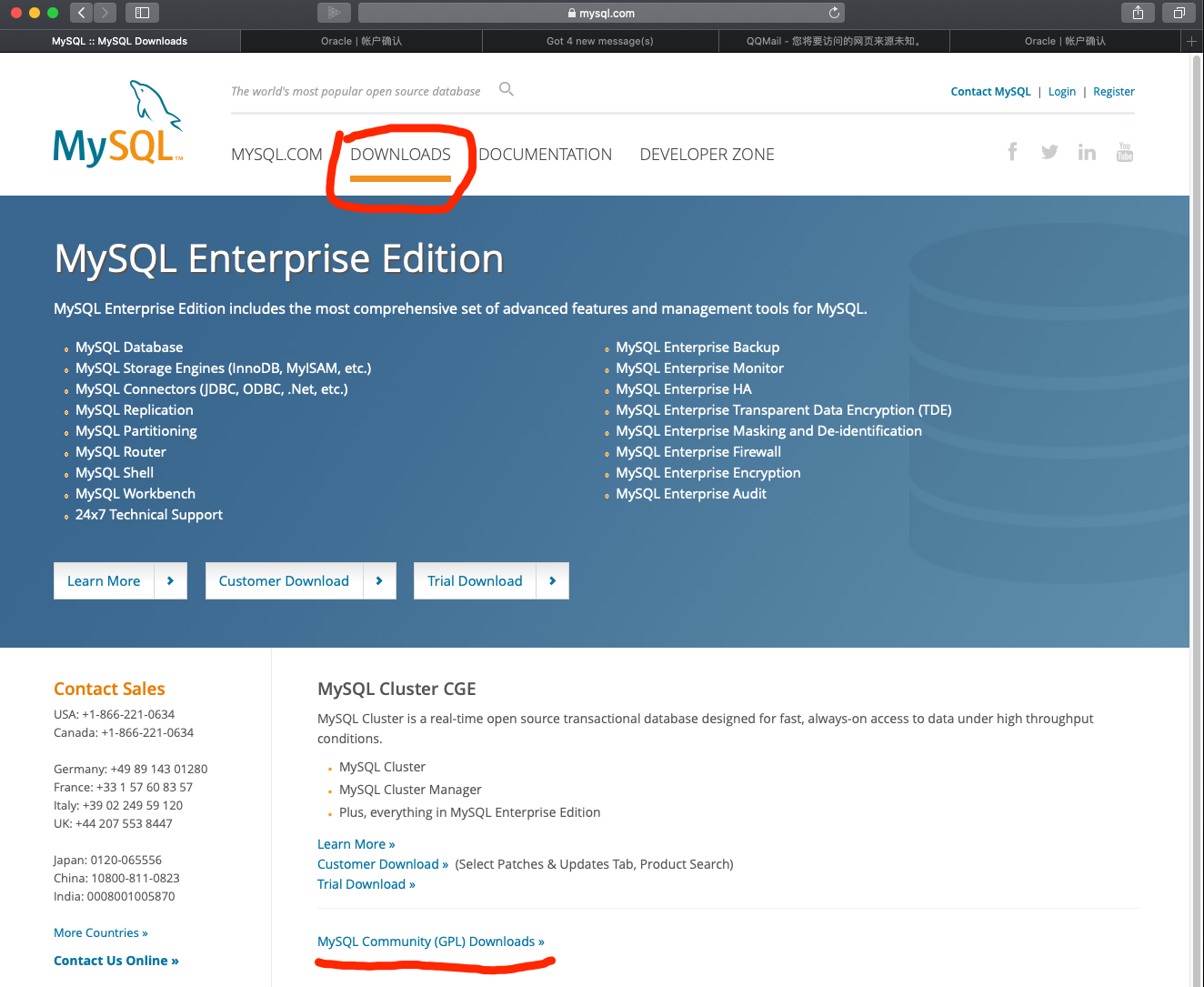
输入网址:
http://www.mysql.com
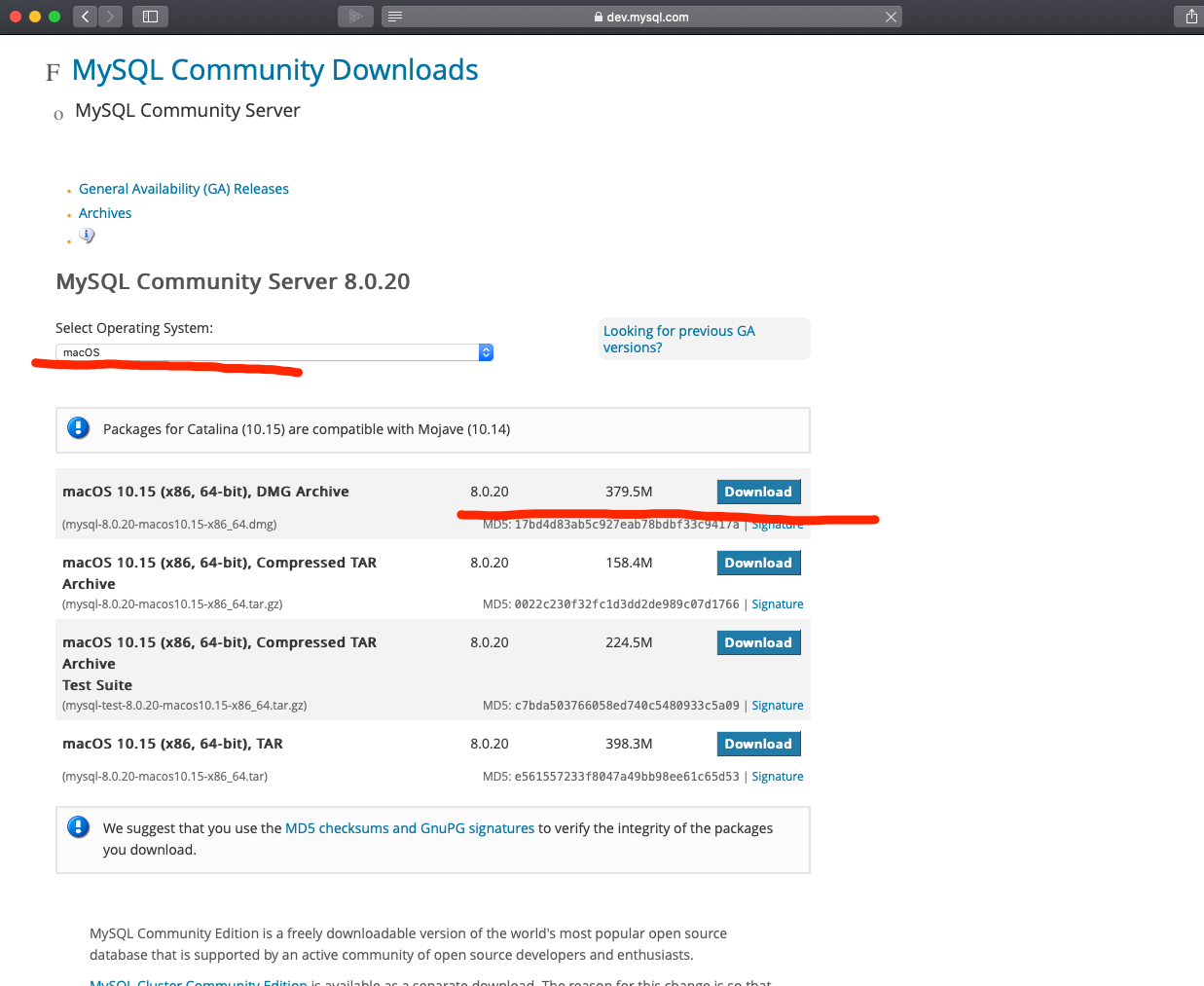
进入Download下载社区版
安装
安装根据操作系统不同稍有差异,以下以macos为例:
在最后输入数据库的
root用户密码,这个密码很很很重要,需要记清楚, 要求包含字母,数字和别的字符。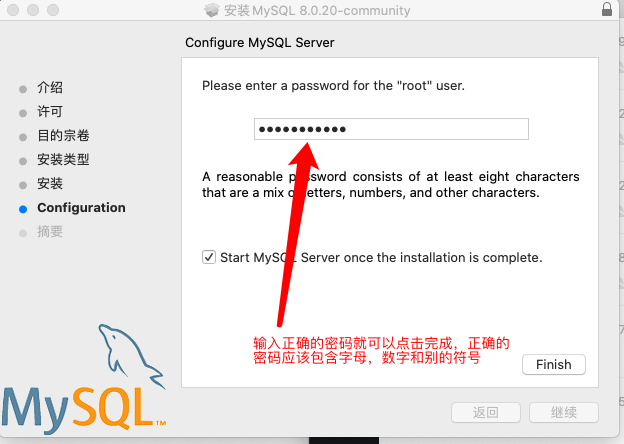
在macos的系统偏好设置中,有新增的mysql图标:
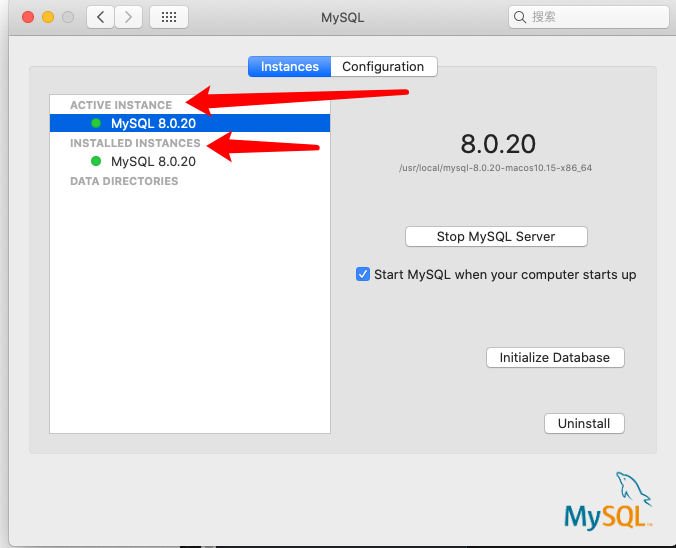
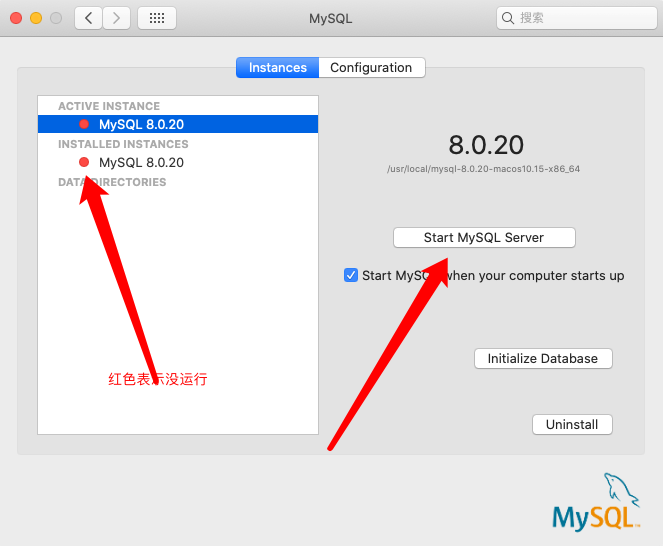
点击后如果是绿色远点,表明mysql服务器在运行中,红色表示停止中, 同时可以点击开始或者关闭数据库。
如果需要初始化数据库,点击后要求同样输入根用户密码
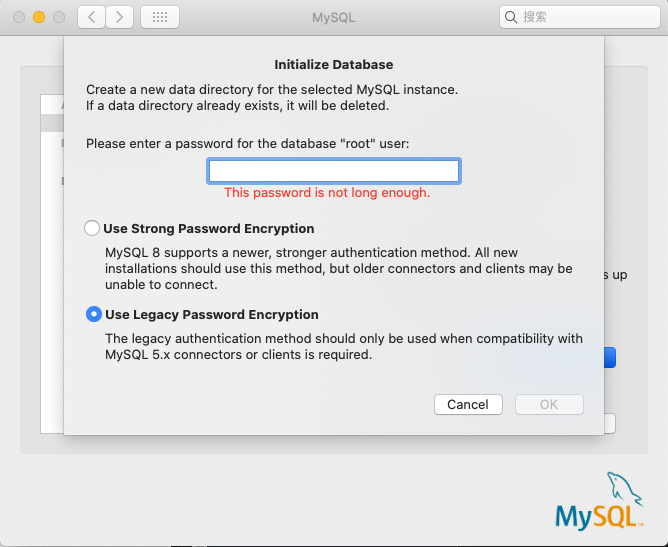
此时基本安装完毕
ubuntu版本安装
ubuntu的安装可以直接使用apt-get 来安装。
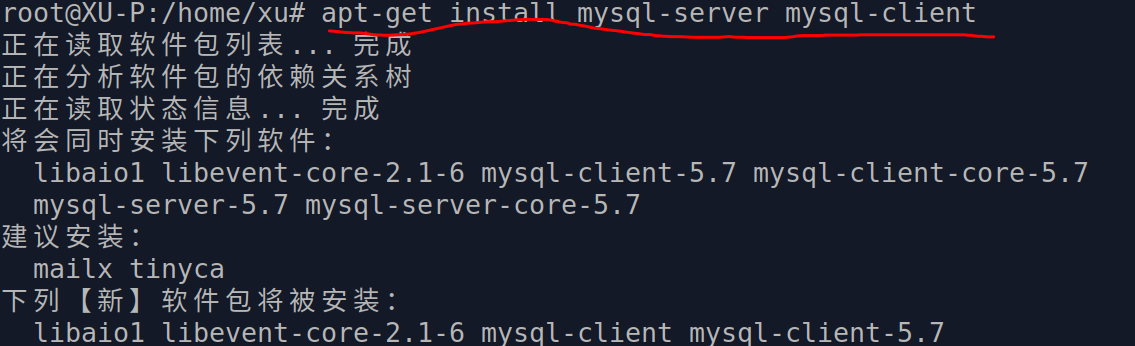
安装后可以直接使用,如下命令即可进入默认的账户, 默认是超级管理员用户:
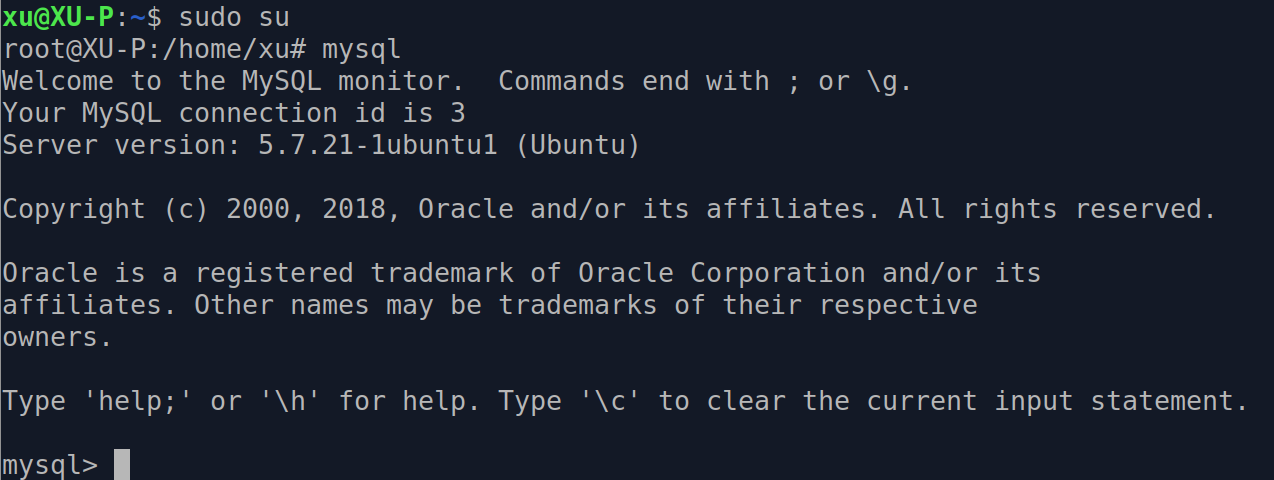
- mysql使用
在mysql的shell中,我们可以基本使用, 比如查看数据库,增删改查 都可以,需要进入到shell环境中。
操作系统一般要求配置环境变量,这样可以直接启动mysql,我没有 配置,所以需要进入到mysql的bin目录下启动:
启动后进入mysql的shell界面,可以进行各种命令行操作。
- 创建数据库
创建数据库tuling, 密码没有。
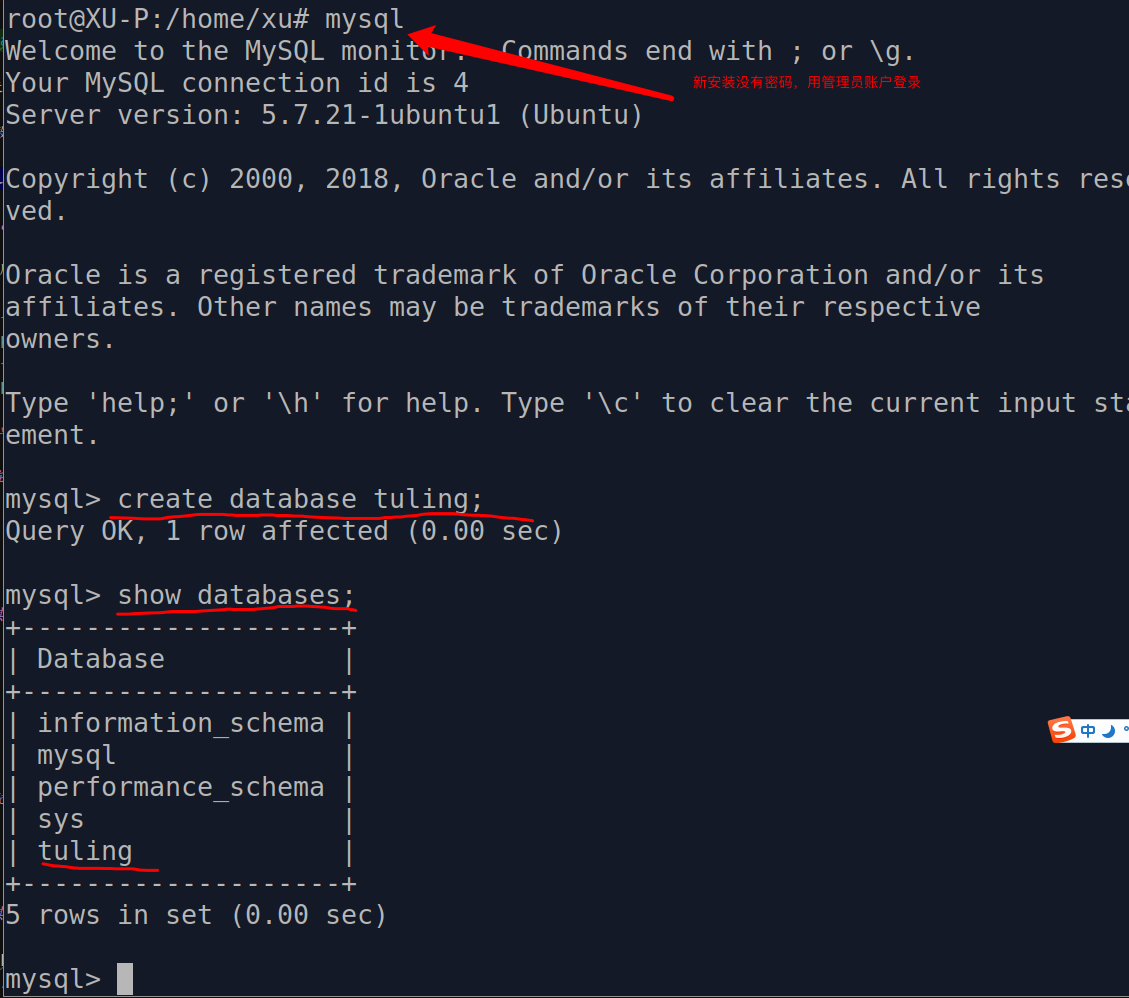
如果只是使用root账户操作MySQL,最后可能会导致Flask访问的时候权限不足。
以下尝试创建用户并授予权限:>sudo su #进入超级管理员 $ mysql #进入mysql数据库 mysql>create database tuling; #创建数据库,名称是tuling # 创建用户tuling, 在任何ip都可以访问,密码是123456 mysql> create user 'tuling'@'%' identified by '123456'; # 授予从任何ip访问的tuling的用户访问数据库tuling任何表格的除了grant外所有权限 mysql> grant all privileges on tuling.* to 'tuling'@'%';
在使用之前需要新创建数据库
6.3.2. Flask插件安装¶
如果使用mysql数据库,需要安装mysqldb:
# 安装mysql数据库支持
pip intall flask-mysqldb
# 安装falsk sqlalchemy
pip install flask-sqlalchemy
6.3.2.1. 在Flask使用SQLAlchemy,需要使用URL进行配置:¶
# 用户名是root,密码mysql, 数据库地址是 127.0.0.1, 端口 3306, 数据库名称 tuling
# 实际使用以你自己的数据库设置为准
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/tuling'
6.3.2.2. 其他常见其他设置:¶
除了一些必须设置的,其他常用的设置还有如下内容:
# 动态追踪修改设置,如未设置只会提示警告
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
6.3.2.3. 其他可能配置:¶
- SQLALCHEMY_DATABASE_URI:
- 用于连接的数据库URI
- 例如:
sqlite:////tmp/test.dbmysql://username:password@server/db
- SQLALCHEMY_BINDS:
- 一个映射 binds 到连接 URI 的字典
- binds 的其他信息见用 Binds 操作多个数据库
- SQLALCHEMY_ECHO:
- 如果为Ture,SQLAlchemy 会记录所有发给 stderr 的语句,对调试有用
- SQLALCHEMY_RECORD_QUERIES:
- 可以用于显式地禁用或启用查询记录
- 查询记录,在调试或测试模式自动启用
- 更多信息见get_debug_queries()
- SQLALCHEMY_NATIVE_UNICODE:
- 可以用于显式禁用原生 unicode 支持
- 当使用不合适的指定无编码的数据库默认值时
- 这对于一些数据库适配器是必须的
- SQLALCHEMY_POOL_SIZE:
- 数据库连接池的大小
- 默认是引擎默认值(通常 是 5 )
- SQLALCHEMY_POOL_TIMEOUT:
- 设定连接池的连接超时时间
- 默认是 10
- SQLALCHEMY_POOL_RECYCLE:
- 多少秒后自动回收连接
- 这对MySQL是必要的,它默认移除闲置多于8小时的连接
- 注意如果 使用 MySQL,Flask-SQLALchemy自动设定这个值为2小时
6.3.2.4. 连接其他数据库¶
SQLAlchemy官方文档有详细的连接各种数据库说明,这里列出一些常用的:
Postgres:
postgresql://scott:tiger@localhost/mydatabase
MySQL:
mysql://scott:tiger@localhost/mydatabase
Oracle:
oracle://scott:tiger@127.0.0.1:1521/sidname
SQLite(注意开头的四个斜线):
sqlite:////absolute/path/to/foo.db
6.4. SQLAlchemy¶
使用Flask的ORM一般的步骤是:
- 配置相应数据库
- 利用ORM定义相应的模型
- 利用数据库查询工具进行操作
使用ORM主要是为了利用Python的面向对象编程,我们在定义一个类的属性的时候, 需要用到的属性类型一般都是SQLAlchemy定义好的,常用的属性类型是:
Integer: int, 普通整数,一般是32位
SmallInteger: int, 取值范围小的整数,一般是16位
BigInteger: int或long, 不限制精度的整数
Float: float, 浮点数
Numeric: decimal.Decimal, 普通整数,一般是32位
String: str, 变长字符串
Text: str, 变长字符串,对较长或不限长度的字符串做了优化
Unicode: unicode, 变长Unicode字符串
UnicodeText: unicode, 变长Unicode字符串,对较长或不限长度的字符串做了优化
Boolean: bool, 布尔值
Date: datetime.date, 时间
Time: datetime.datetime, 日期和时间
LargeBinary: str, 二进制文件
下面示例代码定义了一个模型类,使用SQMAlchemy定义的类型:
db = SQLAlchemy(app)
7. 数据库模型,跟mysql内书库表结构保持一致¶
class Student(db.Model):
__tablename__ = 'stu'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50), unique=True)
email = db.Column(db.String(100))
pwd = db.Column(db.String(50))
def __str__(self):
return self.name
7.1. 常用的SQLAlchemy创建模型用到的列选项¶
- primary_key: 如果为True,代表表的主键
- unique: 如果为True,代表这列不允许出现重复的值
- index: 如果为True,为这列创建索引,提高查询效率
- nullable: 如果为True,允许有空值,如果为False,不允许有空值
- default: 为这列定义默认值
7.2. 常用的SQLAlchemy创建模型的关系选项¶
- backref: 在关系的另一模型中添加反向引用
- primary join: 明确指定两个模型之间使用的联结条件
- uselist: 如果为False,不使用列表,而使用标量值
- order_by: 指定关系中记录的排序方式
- secondary: 指定多对多关系中关系表的名字
- secondary join: 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件
7.3. Flask数据库基本操作¶
注意: 如果操作数据库,暂时需要先手动利用Mysql建立数据库表,例如:
mysql> create table tuling_student (
id int not null auto_increment,
name varchar(20) not null,
email varchar(20) not null,
address varchar(5),
primary key (id))
Flask中使用数据库基本步骤是:
- 准备session,在Flask-SQLAlchemy中,插入、修改、删除操作,均由数据库会话(db.session)管理
- 数据操作写入session中,此处session是数据库会话,不是网络请求会话
- 如果没问题,会话提交(db.commit),提交后实时更改数据库内容。
- 如果写入过程中发送错误,会话回滚(db.session.rollback),恢复到数据库提交前的状态
- 在Flask-SQLAlchemy中,查询操作是通过query对象操作数据。最基本的查询是返回表中所有数据,可以通过过滤器进行更精确的数据库查询。
添加操作
增加内容可以使用session中的添加函数:
db.session.add(obj): 向session中添加一个object
db.session.add_all(list_of_obj): 向session中添加一个object组成的list
@app.route("/add/<string:name>") def add_user(name): stu = Student(name=name, email="3794529@qq.com", pwd="123456") db.session.add(stu) db.session.commit() return "ADD DONE" @app.route("/addall") def add_users(): s1 = Student(name="ly1", email="3794529@qq.com", pwd="123456") s2 = Student(name="ly2", email="3794529@qq.com", pwd="123456") s3 = Student(name="ly3", email="3794529@qq.com", pwd="123456") s4 = Student(name="ly4", email="3794529@qq.com", pwd="123456") db.session.add_all([s1, s2, s3, s4]) db.session.commit() return "ADD DONE"
以上代码执行后的结果按照先后顺序是:
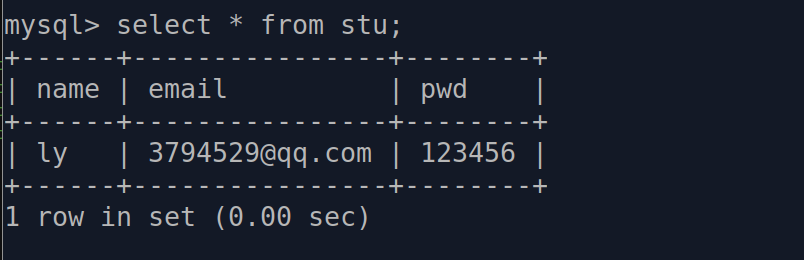
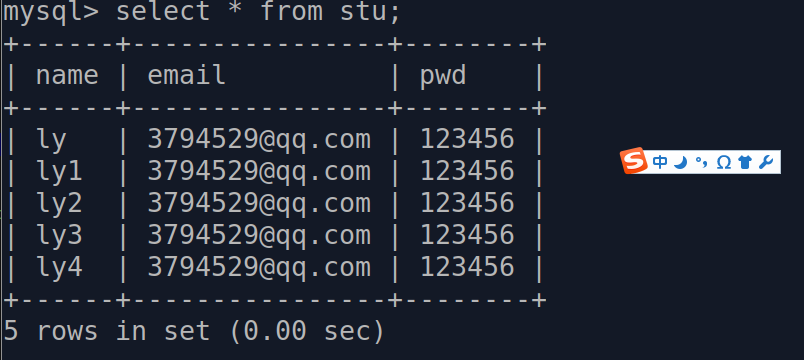
通用查询方法
- 查找操作一般使用如下方式
ModelName.query.query_methode - 查找行为为查询执行和结果过滤两类方法
- 查询条件分为精准查询和模糊查询
- 查找操作一般使用如下方式
查询函数
查询执行器:
all: 以列表形式返回查询的所有结果 >>>Student.query.all() [<Student 1>, <Student 2>, <Student 3>, <Student 4>, <Student 5>]
first: 返回查询的第一个结果,如果未查到,返回None
Student.query.first() <Student 1>
first_or_404: 返回查询的第一个结果,如果未查到,返回404
get: 返回指定主键对应的行,如不存在,返回None
get_or_404: 返回指定主键对应的行,如不存在,返回404
下图是在Shell环境下操作,使用Student.query.get_or_404,数据库表中并没有ID为98的内容, 则由代码可以看出,此操作直接引发NotFound异常。
>>>Student.query.get_or_404(98) Traceback (most recent call last): File "<input>", line 1, in <module> File "/sw/ana/envs/tuling_flask/lib/python3.6/site-packages/flask_sqlalchemy/__init__.py", line 424, in get_or_404 abort(404, description=description) File "/sw/ana/envs/tuling_flask/lib/python3.6/site-packages/werkzeug/exceptions.py", line 822, in abort return _aborter(status, *args, **kwargs) File "/sw/ana/envs/tuling_flask/lib/python3.6/site-packages/werkzeug/exceptions.py", line 807, in __call__ raise self.mapping[code](*args, **kwargs) werkzeug.exceptions.NotFound: 404 Not Found: The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.
count: 返回查询结果的数量
paginate: 返回一个Paginate对象,它包含指定范围内的结果
查询过滤器:
filter: 把过滤器添加到原查询上,返回一个新查询,注意查询条件的写法
s = Student.query.filter(Student.name=="ly")
filter_by: 把等值过滤器添加到原查询上,返回一个新查询,注意查询条件的写法
s = Student.query.filter_by(name="ly")
limit: 使用指定的值限定原查询返回的结果
Student.query.filter(Student.name.contains('ly')).limit(2)
offset: 偏移原查询返回的结果,返回一个新查询
>>> s =Student.query.filter(Student.name.contains('ly')) s.count() 5 >>> s =Student.query.filter(Student.name.contains('ly')).offset(3) >>> s.count() 2
order_by: 根据指定条件对原查询结果进行排序,返回一个新查询
group_by: 根据指定条件对原查询结果进行分组,返回一个新查询
常用精准查询方法:
filter
结果是baseQuery objects
过滤条件的格式:对象.属性==值
studnets = Student.query.filter(Student.id==1)
filter_by
结是baseQuery objects,可以进行遍历
students = Student.query.filter_by(id=1)
原生sql
结果是一个可以遍历的对象
sql = 'select * from student where id=1;' students = db.session.execute(sql)
常用模糊查询
语法:
filter(模型名.属性.运算符('xx'))运算符:
contains:包含startswith:以什么开始endswith:以什么结束in_:在范围内>>> s =Student.query.filter(Student.name.in_(['ly1','ly2','ly3'])) >>> s.count() 3
like:模糊__gt__: 大于__ge__:大于等于__lt__:小于__le__:小于等于
查询条件逻辑运算
与
and_filter(and_(条件),条件…)
案例:
students = Student.query.filter(Student.s_age==16, Student.s_name.contains('花')) students = Student.query.filter(and_(Student.s_age==16, Student.s_name.contains('花')))
或
or_filter(or_(条件),条件…)
案例:
students = Student.query.filter(or_(Student.s_age==16, Student.s_name.contains('花')))
非
not_filter(not_(条件),条件…)
案例:
students = Student.query.filter(not_(Student.s_age==16), Student.s_name.contains('花'))
update操作
更新记录可以直接修改记录属性,最后commit就可以>>>s = Student.query.all()[0] >>>s <Student 1> >>>s.name 'ly' >>>s.name = "NewName" >>>db.session.commit() >>>s = Student.query.all()[0] >>>s.name 'NewName'
delete操作
delete操作使db.session.delete(obj)就可以,使用commit提交生效>>>ss = Student.query.all() >>>len(ss) 4 >>>s = ss[0] >>>db.session.delete(s) >>>db.session.commit() >>>ss = Student.query.all() >>>len(ss) 3
几点说明
- fliter和filter_by的结果可遍历
- 可以通过对其结果使用all()方法将其转换成一个列表或者first()转换成objects对象。
- all()获得的是列表,列表没有first()方法
- fliter和filter_by有flrst()方法,没有last方法
Flask模型和Django的区别:
模型中数据库的表名的默认值:
- 在django中默认表名为:
应用appming_模型名小写 - 在flask中默认的表名为:模型名的小写
- 在django中默认表名为:
主键自增字段:
django中会默认创建自增的主键id
flask中需要手动创建自增的id:
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
3.查询所有数据的结果all
- 在django结果中查询的结果是QuerySet
- 在flask中查询结果是List
4.查询满足条件的数据的结果 filter()
- 在django查询结果是QuerySet
- 在flask中查询结果是baseQuery objects
7.4. Flask数据库表关系¶
一般数据库表关系分为三种:
- 一对一(OneToOne,1:1)
- 一对多(OneToMany, 1:N)
- 多对多(MonyToMany, N:N)
一般来说,定义关系需要两步, 分别是创建外检和定义关系属性,对于更复杂的多多的,还需要定义关联表来管理关系。
我们先从一对多开始讲起,一对一看做是一对多的特例就可以起。
7.4.1. 一对多关系¶
一对多关系的定义步骤:
在多的那一方定义外键
此时会在多的那一方的数据库表中添加一个字段,名称就是你定义的外键的名称,例如: buser_id = db.Column(db.Integer, db.ForeignKey("dbuser.id")) 会在数据库表中添加一个叫 buser_id 的字段,本字段的值为 数据库表 dbuser 中字段 id 的值在一的那一方添加关系属性
定义一个关系属性,这个关系属性不会在数据库表中添加字段, 后续可以通过定义的这个关系属性直接获取相对应的实例。 格式如下: blogs = db.relationship('Blog')
案例使用博客论坛。
考虑有博客Blog和用户BUser之间的关系,我们希望一个用户当然可以发N多篇文章,但 论坛的文章一般没有多个作者的情况,所以,这里我们把这种关系定义为一对多的关系。
7.4.1.1. 创建Models¶
创建模型后如下代码:
# 数据库模型,跟mysql内书库表结构保持一致
class BUser(db.Model):
__tablename__ = "dbuser"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50), unique=True)
email = db.Column(db.String(100))
pwd = db.Column(db.String(50))
# 参数为模型名称
# 属性名称没有限制,不会作为字段写入数据库表中
blogs = db.relationship('Blog')
def __str__(self):
return self.name
class Blog(db.Model):
__tablename__ = "blog"
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(50), unique=True)
content = db.Column(db.Text(500))
blog_type = db.Column(db.Integer)
# 在多的一方添加外键, dbuser.id中的dbuser指的是数据库表名称, id是属性
# 会在Blog模型的数据库表中添加一个字段-"buser_id"
buser_id = db.Column(db.Integer, db.ForeignKey("dbuser.id"))
添加完后数据库内容如下: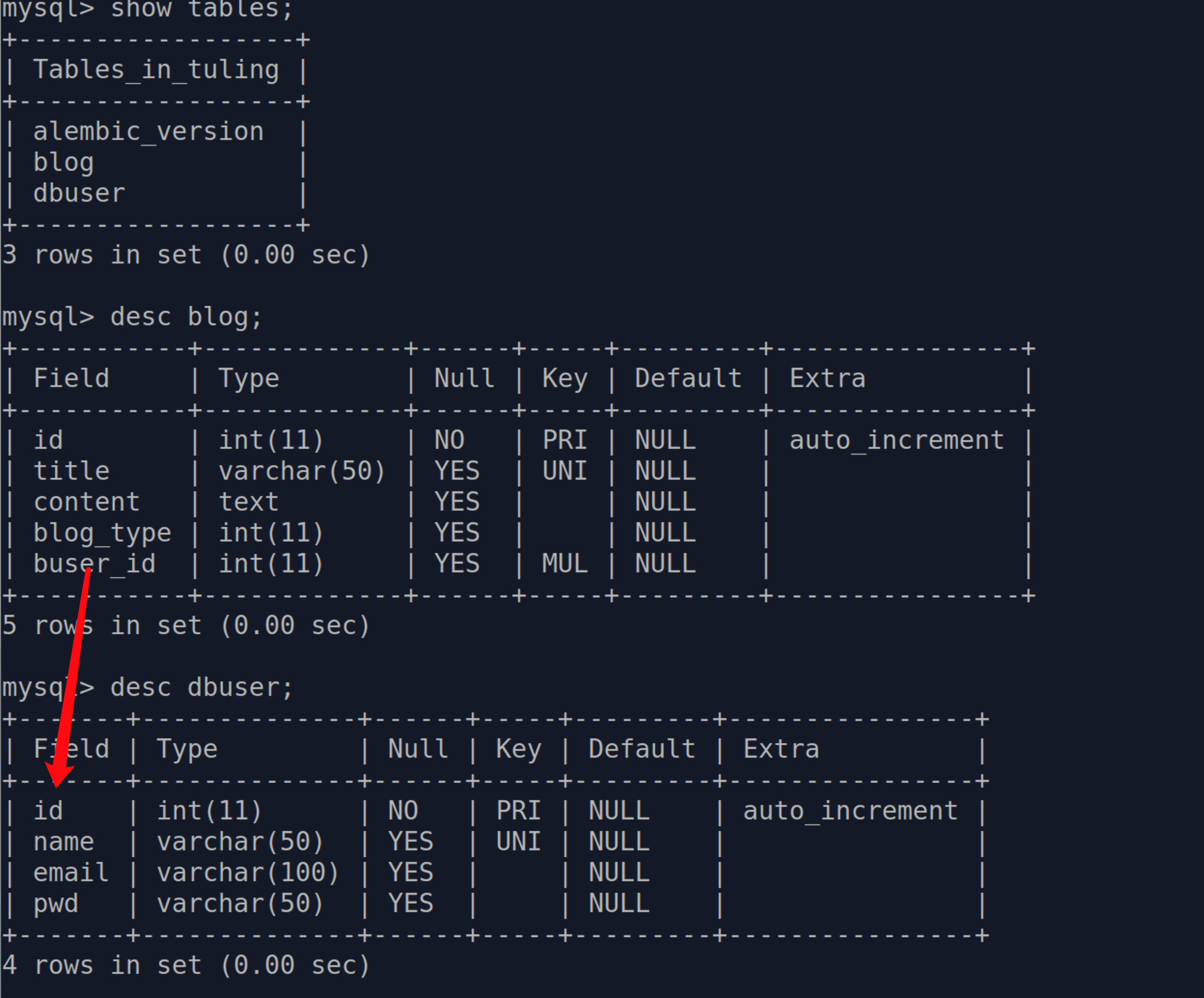
7.4.1.2. 添加内容并创建关系¶
添加用户
u1 = BUser(id=1, name="dana01", email="3794529@qq.com") u2 = BUser(id=2, name="dana02", email="3794529@qq.com", pwd="123123") db.session.add_all([u1, u2]) db.session.commit()
添加blog
blog1= Blog(id=100, title="tuling-title-01", content="tuling-content-01", blog_type=1) blog2 = Blog(id=101, title="tuling-title-02", content="tuling-content-02") blog3 = Blog(id=102, title="tuling-title-03", content="tuling-content-03") db.session.add_all([blog1, blog2, blog3]) db.session.commit()
添加关系
添加关系有两种情况,分别是通过外键
blog1.buser_id = 2 blog2.buser_id = 1 db.session.commit()
添加完毕后结果如图所示:
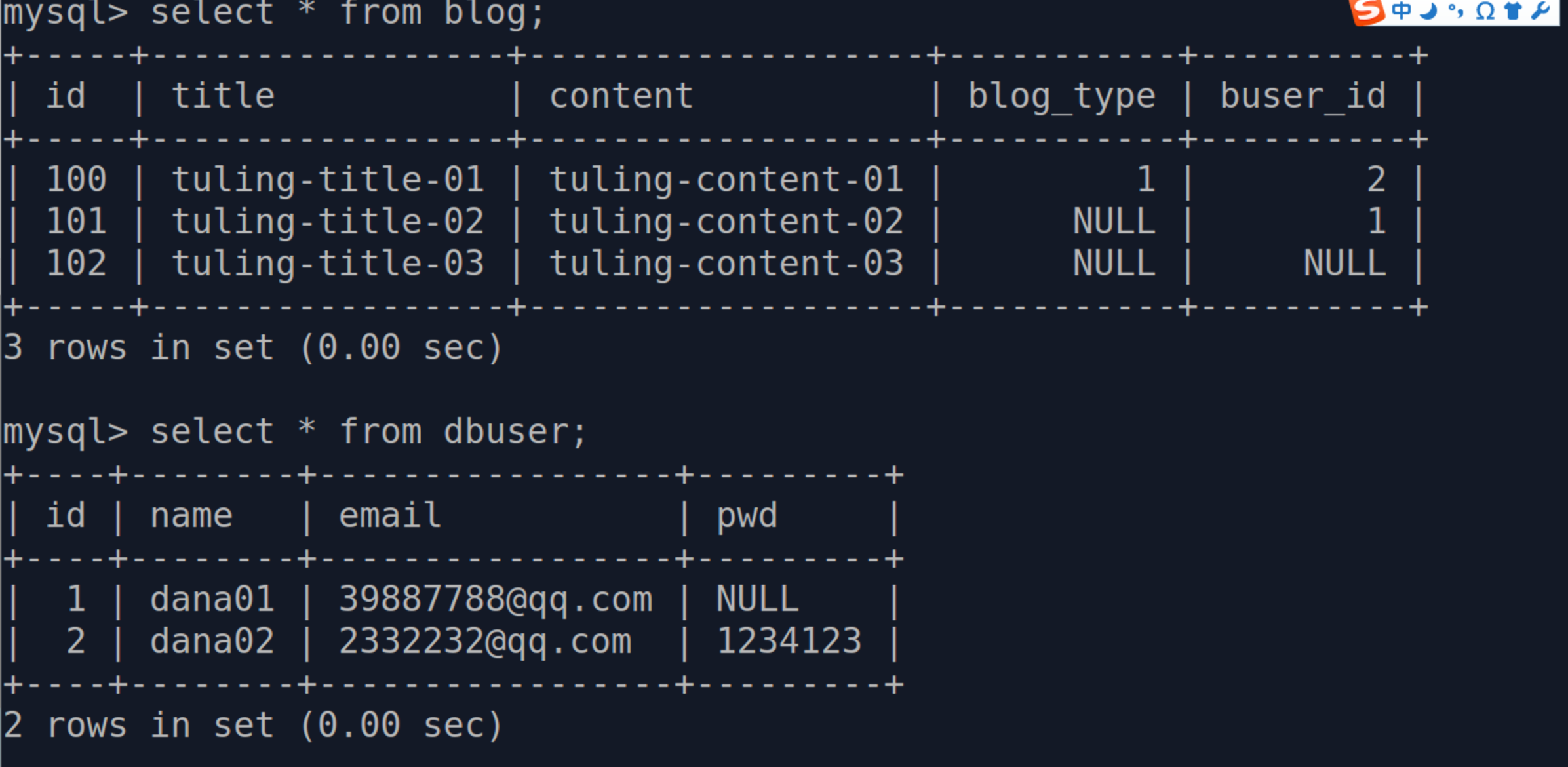
通过关系属性 通过关系属性可以直接添加,此时把属性当做一个列表,需要添加的内容直接放入列表即可。
以下为Shell操作内容:>>>u = BUser.query.get(1) >>>u <BUser 1> >>>u = BUser.query.get(2) >>>u <BUser 2> >>>u.blogs [<Blog 100>] >>>blogs = Blog.query.get(102) >>>blogs <Blog 102> >>>u.blogs.append(blogs) >>>u.blogs [<Blog 100>, <Blog 102>] >>>db.session.commit()
操作完毕后数据库如下:
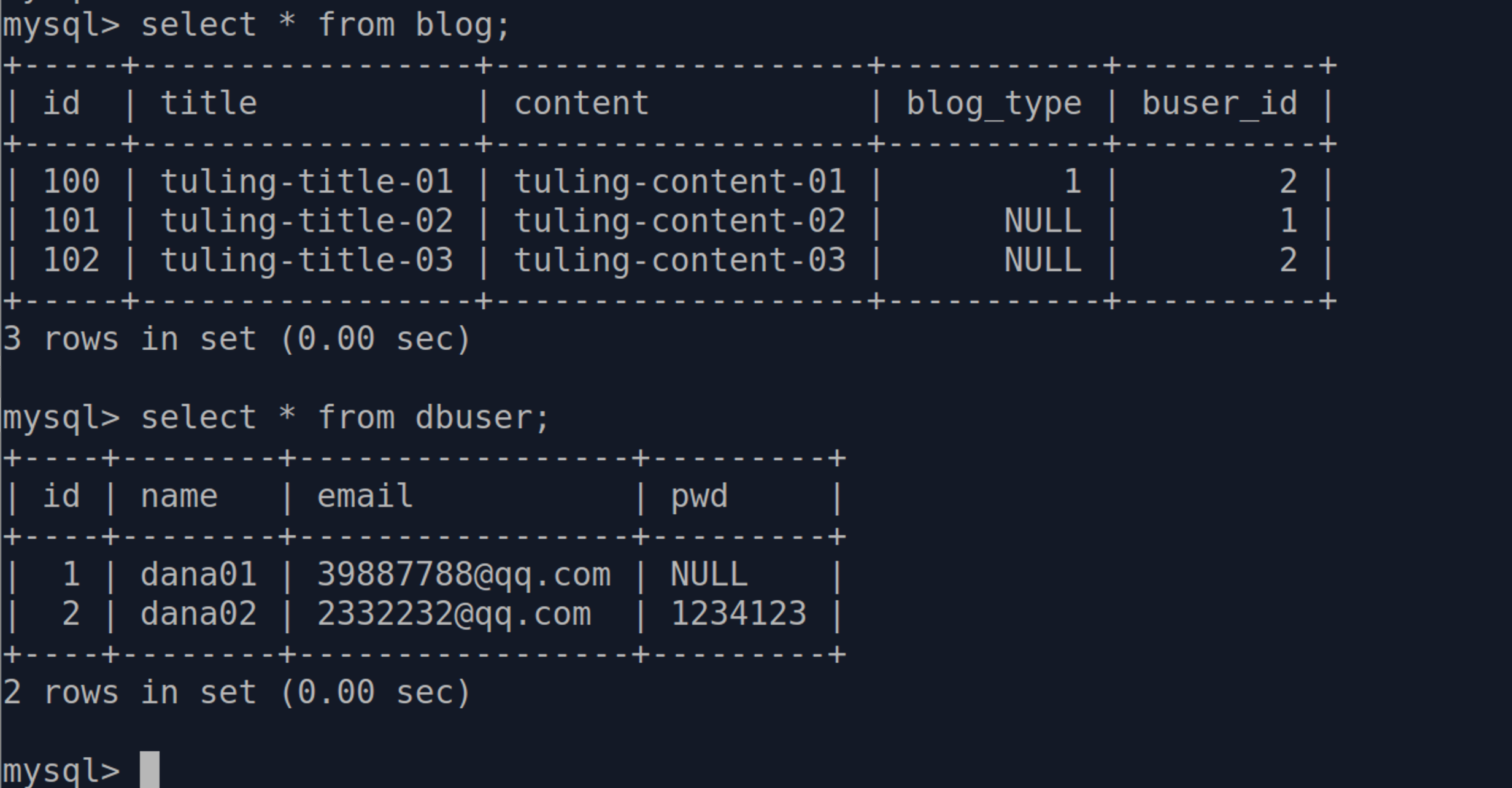
7.4.1.3. 查找和删除¶
如果把关系看做列表,外键看做一个值,则查找和删除就简单的多了。
查找直接使用值或者列表就可以
删除直接操作 关系SQLAlchemy会自动为我们管理,不需要其他太多操作。如下操作:
>>>u.blogs[1].title 'tuling-title-03' >>>del u.blogs[1] >>>db.session.commit()
7.4.2. 关系相关属性¶
在数据库中两个表产生关系其实是通过一个表中增加一个多余的字段,用来存储相应联系的的另一个关联表中记录的id,
同时,另一个表中虽然不存储相应的对方id, 为了方便我们访问,我们可以定义一个所谓的关系,通过定义的关系,
我们可以把关系当做一个属性直接访问另一个表中的对应记录。
在关系函数中,有很多参数用来设置查询时候的具体行为,我们在SQLAlchemy中也对此类参数进行了很好的模拟,常见的定义关系时候的参数有:
- back_populates: 定义反向引用,用于建立双向关系。使用的时候需要在关系的两侧都显示定义。
- backref: 添加反向引用。使用他只需要在双向关系的一侧使用,使用back_popuates的简写。
- lazy: 加载记录的方式,详见下表。
- userlist: 是否使用列表的形式加载记录,如果为False则使用标量的方式加载记录。
- cascade: 记录的级联操作,
- order_by: 加载记录的石红的排序方式
- secondary: 多对多关系中制定相关关联表
- primaryjoin: 指定多对多关系中的一级联结条件
- secondaryjoin: 指定多对多关系中的二级联结条件
记录的加载方式使用lazy参数设置,lazy相关的取值和含义如下:
select: 等同lazy=True,必要时一次性加载记录,返回包含记录的列表
joined: 等同lazy=False, 和父级查询一样加载记录
immediate:一旦父级查询加载就立即加载
subquery: 用于子查询,类似joined
dynamic: 不直接加载记录,而是返回一个包含相关记录的query对象,可以让后面继续的附加查询函数对结果进行过滤
数据库关系参数案例:
学校(School)和老师(Teacher)是一对多的关系,我们想定义一个双边的关系,通过学校能查到老师的信息,通过老师可以 查到所属学校的信息,我们可以在两边使用back_propulates进行定义一个双边关系, 此案例我们在定义双边关系的时候使用backref进行简化, 代码参加v5/rels.py:class School(db.Model): __tablename__ = "school" id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) addr = db.Column(db.String(100)) teachers = db.relationship("Teacher", backref='school') def __str__(self): return self.name class Teacher(db.Model): __tablename__ = "teacher" id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) school_id = db.Column(db.Integer, db.ForeignKey("school.id")) def __str__(self): return self.name
上述案例在定义关系
teachers的时候使用了参数backref定义了一个反向关系,在我们实际使用当中对Teacher的实例可以 通过属性school关系进行访问老师对应的学校实例。>>>t = Teacher.query.get(1) >>>t <Teacher 1> >>>t.school <School 1>
7.4.3. 一对一关系¶
一对一关系可以看做一对多关系的特例。
具体使用也跟一对多关系类似,只不过需要注意:
- 要确保关系两侧的关系属性都是标量属性,都只返回单个值
- 所以要在定义集合属性的关系函数中将uselist参数设为False
案例, 国家(Contry)和首都(Capital)一般看做一对一的关系,先定义模型,参见代码v5/country.py:
class Country(db.Model):
id = db.Column(db.Integer, primary_key = True)
name = db.Column(db.String(30), unique = True)
capital = db.relationship('Capital', uselist=False)
def __repr__(self):
return '<Country %r>' % self.name
class Capital(db.Model):
id = db.Column(db.Integer, primary_key = True)
name = db.Column(db.String(30), unique = True)
country_id = db.Column(db.Integer, db.ForeignKey('country.id'))
country = db.relationship('Country')
def __repr__(self):
return '<Capital %r>' % self.name
对数据库进行钱以后,可以进行相应的操作。
对相应数据记录的添加和查找如下:
c = Country(id=1, name="china")
cap = Capital(id=1, name="beijing", country_id=1)
db.session.add_all([c,cap])
db.session.commit()
c = Country.query.get(1)
c.capital
<Capital 'beijing'>
cap = Capital.query.get(1)
cap.country
<Country 'china'>
添加记录后的数据库如下:
mysql> select * from capital;
+----+---------+------------+
| id | name | country_id |
+----+---------+------------+
| 1 | beijing | 1 |
+----+---------+------------+
1 row in set (0.00 sec)
mysql> select * from country;
+----+-------+
| id | name |
+----+-------+
| 1 | china |
+----+-------+
1 row in set (0.00 sec)
7.4.4. 多对多关系¶
多对多关系的建立,需要借助一个单独的表,用来存储关系。 多对多建立的一般步骤是:
- 建立两个实体表
- 增加建立一个关系表,表只有两个内容,分别是两个实体表的外键
- 两个实体表中分别添加关系,关系参数
secondary进行设置
7.4.4.1. 多对多案例¶
老师和学生是通常意义上的多多多关系,即一个老师可以有多个学生,一个学生也可以有多个老师,即 Student:Teacher = N:N。
代码参看./v5/rel_nn.py:
建立两个实体表:
class Student(db.Model): __tablename__ = "student" id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) def __str__(self): return self.name class Teacher(db.Model): __tablename__ = "teacher" id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) def __str__(self): return self.name
增加一个独立的关系表,内容只有两个外键
tb_rel_nn = db.Table("tb_rel_nn", db.Column('student_id', db.Integer, db.ForeignKey('student.id')), db.Column('teacher_id', db.Integer, db.ForeignKey('teacher.id')) )
在实体表中添加关系属性
需要注意的是,关系属性添加的时候需要使用
secondary关键之指出关系表:class Student(db.Model): __tablename__ = "student" id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) teachers = db.relationship("Teacher", secondary=tb_rel_nn, back_populates='students') def __str__(self): return self.name class Teacher(db.Model): __tablename__ = "teacher" id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) students = db.relationship("Student", secondary=tb_rel_nn, back_populates='teachers') def __str__(self): return self.name
7.4.4.2. 多对多关系的CRUD¶
多对多关系中,对表的增删改查直接通过关系修改就可以,把关系当做列表,直接对列表进行修改后,SQLAlchemy会自动变更对应的关系。
>>>t1 = Teacher.query.get(1)
>>>t1
<Teacher 1>
>>>ss = Student.query.all()
>>>ss
[<Student 1>, <Student 2>, <Student 3>]
>>>type(ss)
<class 'list'>
>>>t1.students.append(ss[0])
>>>t1.students.append(ss[1])
>>>db.session.commit()
>>>t1.students
[<Student 1>, <Student 2>]
修改后的数据库表如下:
mysql> select * from tb_rel_nn;
+------------+------------+
| student_id | teacher_id |
+------------+------------+
| 1 | 1 |
| 2 | 1 |
+------------+------------+
2 rows in set (0.00 sec)
mysql>
7.4.5. 案例:¶
在一个数据表中,利用SQLAlche对数据表进行增删改查
准备内容:
创建数据库
tuling并创建访问用户tuling的访问权限>sudo su #进入超级管理员 $ mysql #进入mysql数据库 mysql>create database tuling; #创建数据库,名称是tuling # 创建用户tuling, 在任何ip都可以访问,密码是123456 mysql> create user 'tuling'@'%' identified by '123456'; # 授予从任何ip访问的tuling的用户访问数据库tuling任何表格的除了grant外所有权限 mysql> grant all privileges on tuling.* to 'tuling'@'%';
创建需要用到的数据表
stu, 需要注意的是,这个数据库表必须跟用到的模型内容保持一致。mysql> create table stu (id int key default=auto, name varchar(50) , email varchar(100), pwd varchar(50)); Query OK, 0 rows affected (0.01 sec)
Python代码步骤:
对程序进行基本设置:
from flask import Flask # 导入个包包 from flask_sqlalchemy import SQLAlchemy # 参数指明存放模板的文件夹 app = Flask(__name__) # 用户tuling,密码123456, 数据库位置/访问端口/数据库名=127.0.0.1:3306/tuling app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://tuling:123456@127.0.0.1:3306/tuling' db = SQLAlchemy(app)
设置数据模型
# 数据库模型,跟mysql内书库表结构保持一致 class Student(db.Model): __tablename__ = 'stu' id = db.Column(db.Integer, primary_key=True, autoincrement=True) name = db.Column(db.String(50), unique=True) email = db.Column(db.String(100)) pwd = db.Column(db.String(50)) def __str__(self): return self.name
增删查改
@app.route("/add/<string:name>") def add_user(name): stu = Student(name=name, email="3794529@qq.com", pwd="123456") db.session.add(stu) db.session.commit() return "ADD DONE"